概览
AI = Artificial Intelligence = 人工智能
在过去几十年中,人工智能经历了多次兴衰,而今天的 AI(例如 GPT-4、Claude、Gemini)几乎全部建立在深度学习之上。理解现代 AI,其实只需要理解三件事
- 神经网络
- 机器学习
- 大模型
什么是智能
一个系统如果具备下面两个能力,我们就可以称它为智能系统
- 感知环境
- 根据环境做出反应
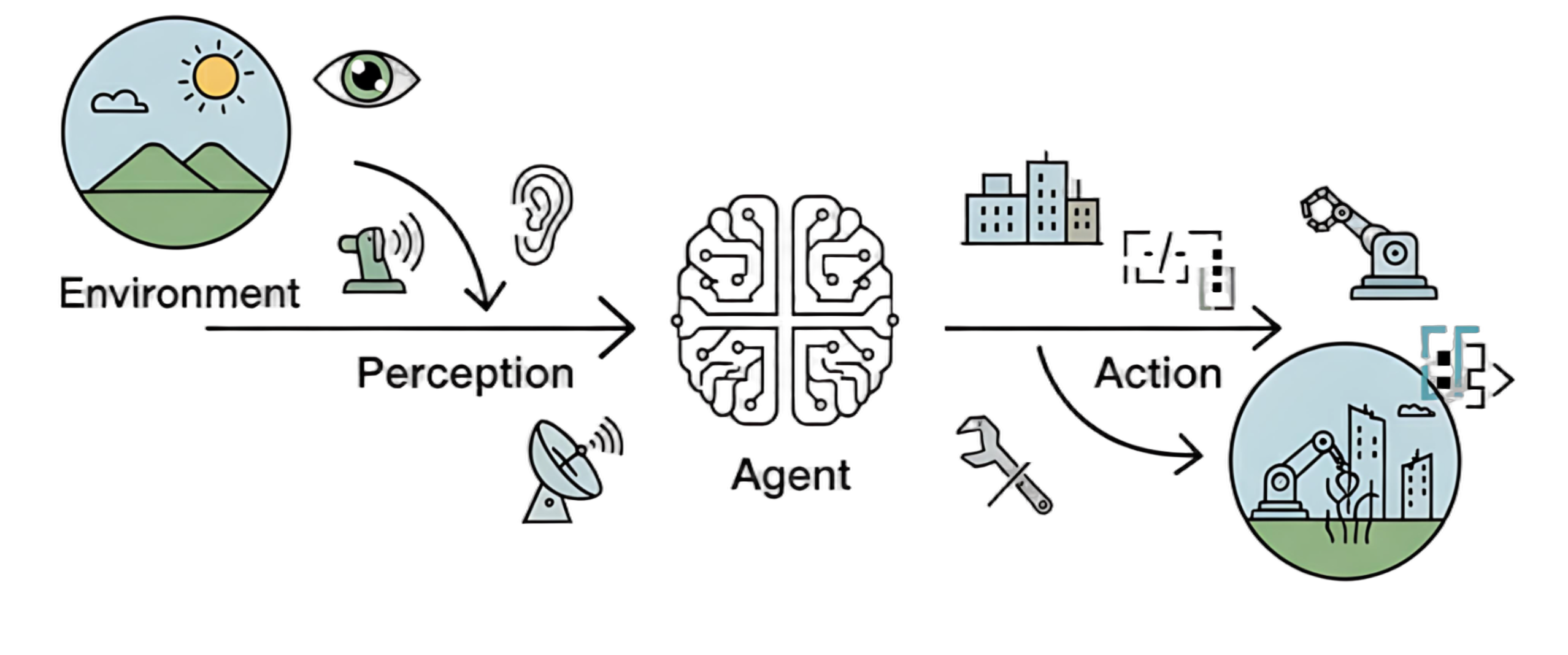
例如:
| 系统 | 感知 | 反应 |
|---|---|---|
| 人类 | 视觉、听觉 | 行动 |
| 自动驾驶 | 摄像头、雷达 | 控制方向 |
| AI 模型 | 文本、图像 | 生成结果 |
所以,智能 = 感知环境 + 做出决策
什么是人工智能
人工智能则顾名思义,人为创造的智能,就是让计算机或机器表现出类似人类智能的行为。也就是机器能够“思考、学习、判断、决策”,在一定程度上像人一样理解和处理信息
例如:
| 系统 | 感知 | 反应 |
|---|---|---|
| 自动驾驶汽车 | 摄像头、雷达 | 转向、加速、刹车 |
| 聊天机器人 | 用户输入文本 | 回复对话 |
| 推荐系统 | 用户历史行为 | 推荐商品或内容 |
人工智能发展中,存在 2 种思想分歧,分为别
- 符号主义
- 连接主义
当今最强大的 AI 系统(如大语言模型)几乎全部基于连接主义路线(尤其是 Transformer + 海量数据 + 巨量计算)的极端形式,而符号主义在需要强逻辑、可解释、规则明确的场景(如某些工业、金融系统)仍有重要价值
为克服上述两种范式的局限,一种“大和解”的思想开始兴起,这就是神经符号主义,也称神经符号混合主义。它的目标,是融合两大范式的优点,创造出一个既能像神经网络一样从数据中学习,又能像符号系统一样进行逻辑推理的混合智能体。它试图弥合感知与认知、直觉与理性之间的鸿沟
符号主义
符号主义的想法是智能 = 逻辑 + 规则。符号主义认为“如果我们把世界知识全部写成规则,机器就能拥有智能”

例如:
如果 发烧 + 咳嗽 + 白细胞升高
那么 可能是肺炎这种系统被称为专家系统(Expert System)
但它存在几个严重问题:
- 智能上限取决于专家:因为需要专家来设置这些特征和推理,专家有多聪明,系统就有多聪明
- 无法学习:智能定格在创建的那一刻,无法主动学习成长
- 非常脆弱:现实世界充满模糊边界,例如轻微发烧、不典型症状、复杂情况等,规则系统很难处理
因此符号主义逐渐衰落
连接主义
连接主义的想法是智能 = 学习 + 连接。连接主义不追求一开始就有一个完美的智能,允许这个智能在引导和学习下越来越好。这也就引申出了另一个概念“机器学习”
连接主义认为“大自然已经给出了实现智能的标准答案,人的大脑”。只需要仿生的方式,模拟单个神经元的功能以及神经元之间复杂的连接,那么运行这个人工搭建起来的神经网络,就能实现人工智能

连接主义有如下特点:
- 简单处理单元(神经元)
- 大量连接
- 通过学习来调整权重
神经网络没有“知识库”,知识其实藏在数十亿个权重参数里面。它是现代 AI 的基础
当然连接主义也是有缺点的
- 黑盒属性:缺乏可解释性,不知道内部具体是如何推理的
- 数据饥渴:样本效率极低,模型通常需要成千上万、甚至上亿规模的数据标注
- 灾难性遗忘:当你训练一个网络学会下围棋后,再教它踢足球,它会迅速“擦除”之前关于围棋的所有权重记忆,变得完全不会下棋
- 缺乏真正的逻辑推理与常识:LLM 幻觉
- 算力与能效比的失衡:资源消耗巨大
Perceptron(感知机)
感知机是神经元的始祖,建模如下。它是一个非常简单的二元分类器,输出只有 {0,1} 或者{-1,1}
激活函数是阶跃函数
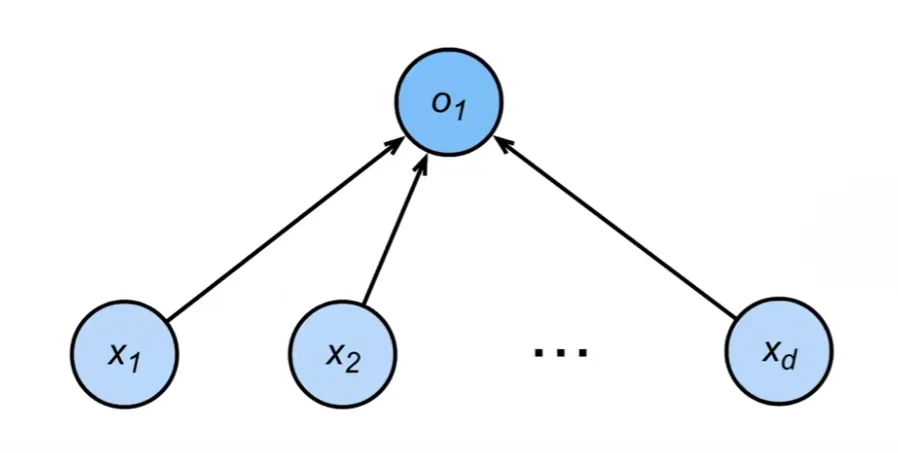
感知机有什么用呢?
我现在有一大堆水果,{"苹果","葡萄","西瓜","橘子"...},我想在其中识别出哪一个是苹果?
人是怎么判断苹果的呢?是通过一些特征累积起来,例如吃起来酸酸甜甜的,个头不大不小,红色的等等。那么同样的
- 我可以通过设置一些特征来描述水果,例如
尺寸的大小,味道,颜色。对于苹果的特征来说尺寸=中等大小,颜色=红色,味道=酸、甜 - 按照特征描述,我设置了如下特征值
特征变量 含义 (x_1) 尺寸大 (x_2) 尺寸小 (x_3) 红色 (x_4) 绿色 (x_5) 黄色 (x_6) 味道甜 (x_7) 味道酸 - 由此特征,公式可得
- 当我调节各个参数(如何调节参数暂时不考虑)的权重,使得
- 输入苹果的参数,y = 1
- 输入其他水果的参数,y = 0
- 完成苹果的识别

感知机有个巨大的缺陷,它只能做线性分类,即无法表示 XOR(异或)这类的非线性算法。

单层感知机的局限性 + 缺乏有效的多层训练算法导致连接主义陷入低谷
多层感知机(Multilayer Perceptron)
后续发现,如果把多个感知机叠加,就可以解决非线性问题,这就是多层感知机(MLP)

多层感知机中间可以嵌套 1-N 层,再配上非线性的激活函数,就可以处理非线性的问题。这也是神经网络的基础骨架
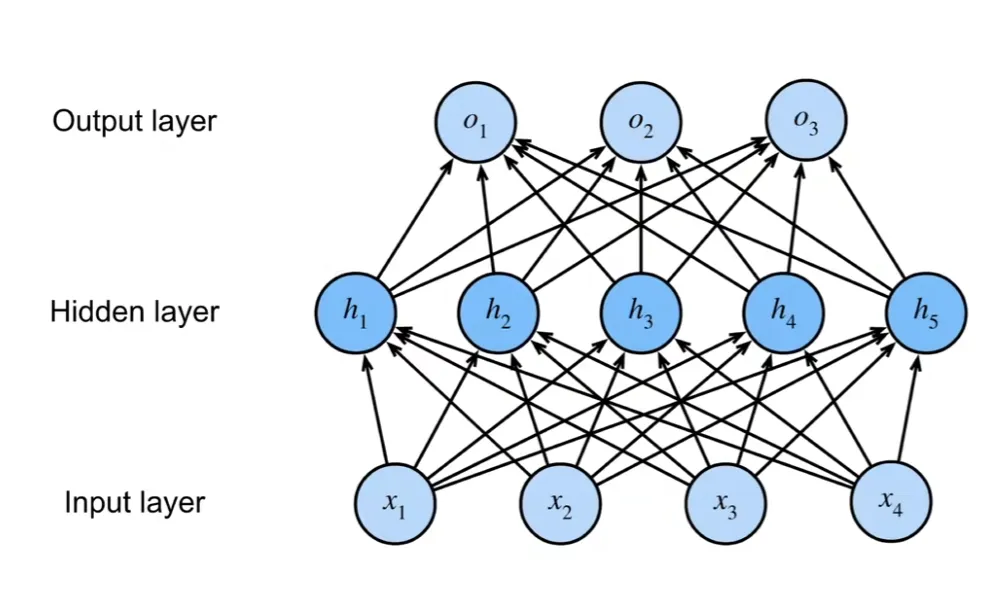
多层感知机 + 反向传播算法让连接主义复苏
神经元
神经元是模拟生物神经元的模型,其实就是带有权重的简单函数。和感知机不同,神经元输出是一个连续的数值(例如 0.72),代表了“激活程度”,可以“丝滑”地微调权重,从而学习极其复杂的特征
n 表示的输入维度 再经过一个 激活函数
可以如此比喻
- 感知机像是一个老式灯泡开关,只能开/光
- 神经元像是一个旋钮式调光器
神经网络
单个神经元的能力非常有限,只能处理非常简单的线性分类。但当成千上万个神经元按照特定的层级结构连接在一起时,就形成了神经网络

随着 AI 的发展,研究者设计了不同的网络结构
前馈神经网络
前馈神经网络 (Feedforward Neural Networks, FNN)
以多层感知机为基础,信息单向传播,输入层 → 隐藏层 → 输出层,没有记忆能力,属于最基础的神经网络结构
卷积神经网络
卷积神经网络 (Convolutional Neural Networks, CNN)引入了卷积核和池化层,极大的减少了参数量。处理具有网格结构的数据,长期统治计算机视觉领域,直到 Vision Transformer 出现
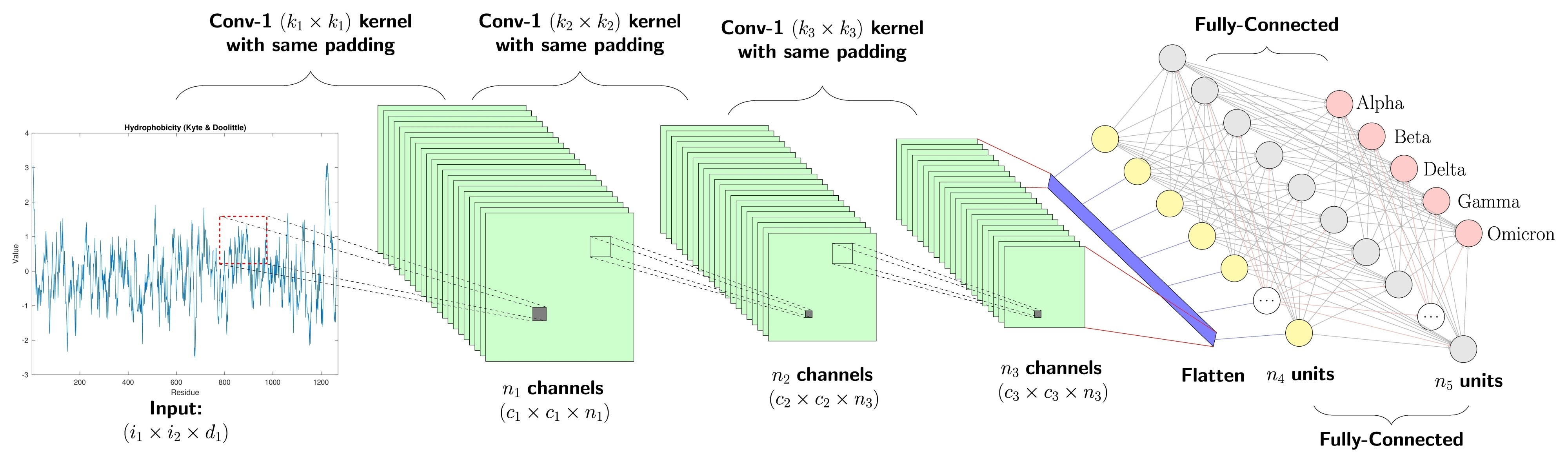
-
局部链接
假设一张图片是
100 * 100,根据 RGB 定义,输入节点则有3 * 100 * 100个,若有 1000 个神经元,则这一层就需要3 * 100 * 100 * 1000个权值参数CNN 认为像素之间的相关性通常是局部的。卷积核(Filter)每次只关注图像的一个小区域
例如一个
3*3的卷积核,一个神经元只需要 9 个权重参数。就像用放大镜观察名画,你不需要一次性盯着整幅画看,而是通过移动放大镜,每次只观察一小块区域1 0 10 1 01 0 1 -
权值共享
在卷积层中,同一个卷积核会滑过整张图片的所有位置,且在所有位置使用的权重参数是完全相同的
-
池化层
池化层本身不含有需要学习的参数,但它通过下采样(Downsampling)显著减少了后续层接收到的特征维度
Vision Transformer
Vision Transformer(ViT)将处理文字的方式,套给了处理图片,将整个图片当成一篇文档来识别。Vision Transformer 在许多视觉任务上超过 CNN,成为新的主流架构之一
循环神经网络
循环神经网络 (Recurrent Neural Networks, RNN)中神经元的输出可以作为输入再次反馈给自己,使其拥有了“短期记忆”。但 RNN 很难处理长序列问题
Transformer
Transformer 抛弃了传统的卷积和循环结构,完全基于自注意力机制 (Self-Attention),解决了 RNN 无法并行计算和长文本遗忘的问题。目前几乎所有大语言模型(LLM)的核心架构
生成式网络
生成式网络 (GAN / Diffusion Models)通过“生成器”和“判别器”相互博弈来生成数据;扩散模型(Diffusion)通过加噪和去噪的过程来生成数据
混合专家模型
混合专家模型 (Mixture of Experts, MoE) 是一种神经网络的架构设计思路。它不再让一个庞大的神经网络处理所有任务,而是将网络拆分成许多个“小专家”,每次只调用最相关的几个来干活。可以类比人类大脑,左边的大脑处理逻辑比较厉害,右边的大脑处理艺术比较厉害
FAQ
什么是激活函数?
激活函数是神经网络的一个信号调节器,激活函数是决定这个神经元输出的关键。
核心功能:引入非线性。无论神经网络有多少层,本质上都是在做线性累加,线性组合嵌套仍然是线性的,这意味着模型只能处理很简单的任务,而激活函数给予了非线性的能力,从而模型能模拟复杂的情况
常用的激活函数有
- Sigmoid
- Relu 及其变体:现代深度网络中最主流的选择
- Softmax
为什么 2018 年之前没人觉得 AI 能这么牛?
- 算力提升:GPU 的算力指数级增加
- 数据支撑:互联网 + 智能手机几乎把知识变成了可爬行的文本
- 算法支撑:Transformer 架构
让 AI = 数据 + 算法 + 算力
为什么大模型会突然变聪明?
研究发现:当模型规模变大时,会出现 涌现能力(Emergent Ability),当模型达到某个规模后,会突然出现新的能力
例如:
- 复杂推理
- 代码生成
- 多语言翻译
- 数学能力
这些能力并不是人为设计的,而是随着模型规模增长 自然出现。这种现象被称为:Scaling Law